5 Ways to Parse JSON Data in Snowflake
In modern data pipelines, JSON has become a standard format for data exchange, particularly when working with APIs, web services, and NoSQL databases like MongoDB. I worked on extracting and modelling MongoDB data in one of my recent projects, and used Snowflake’s powerful capabilities for parsing and querying JSON data.
In this post, I share five different approaches to parsing JSON data in Snowflake that I found useful, using e-commerce data of varying complexity as examples:
- Basic path extraction for simple, consistent JSON structures
- FLATTEN functions when working with arrays that need to be expanded into rows
- Multiple
FLATTENcalls for navigating nested hierarchical data - Semi-structured functions for handling dynamic schemas
- JSON transformation functions when you need to reshape or enrich the data
All examples below parse the column called data from the Snowflake table called test_table.
What is JSON?
JSON (JavaScript Object Notation) is a lightweight data interchange format that’s easy for humans to read and write, and easy for machines to parse and generate. JSON uses a text-based structure with key-value pairs organized into objects (enclosed in curly braces {}) and arrays (enclosed in square brackets []).
Each key-value pair consists of a field name in double quotes, followed by a colon, and then the value, which can be a string, number, boolean (true/false), null, object, or array. For example, the following represents a simple JSON object with three properties:
{
"name": "Wireless Earbuds",
"price": 79.99,
"in_stock": true
}
Approach 1: Accessing simple nested properties with basic JSON path extraction
In e-commerce datasets, product information often comes in nested JSON structures. When you need to extract specific fields and convert them to appropriate data types for analysis, basic path extraction is the simplest approach.
Example JSON Data:
{
"product_id": "P1001",
"product_details": {
"name": "Wireless Earbuds",
"brand": "TechAudio"
},
"price": 79.99,
"in_stock": true,
"last_updated": "2023-09-15T14:30:00Z"
}
Parsing Approach:
Use the colon notation with explicit type casting to extract specific fields:
SELECT
data:product_id::STRING AS product_id,
data:product_details:name::STRING AS product_name,
data:product_details:brand::STRING AS brand,
data:price::FLOAT AS price,
data:in_stock::BOOLEAN AS availability,
data:last_updated::TIMESTAMP_NTZ AS update_timestamp
FROM test_table;
This approach is straightforward and efficient for simple JSON structures. The double-colon (::) operator converts the extracted JSON values to Snowflake native data types. Without type casting, Snowflake would return the values as VARIANT type, which might not work correctly with aggregations or joins.
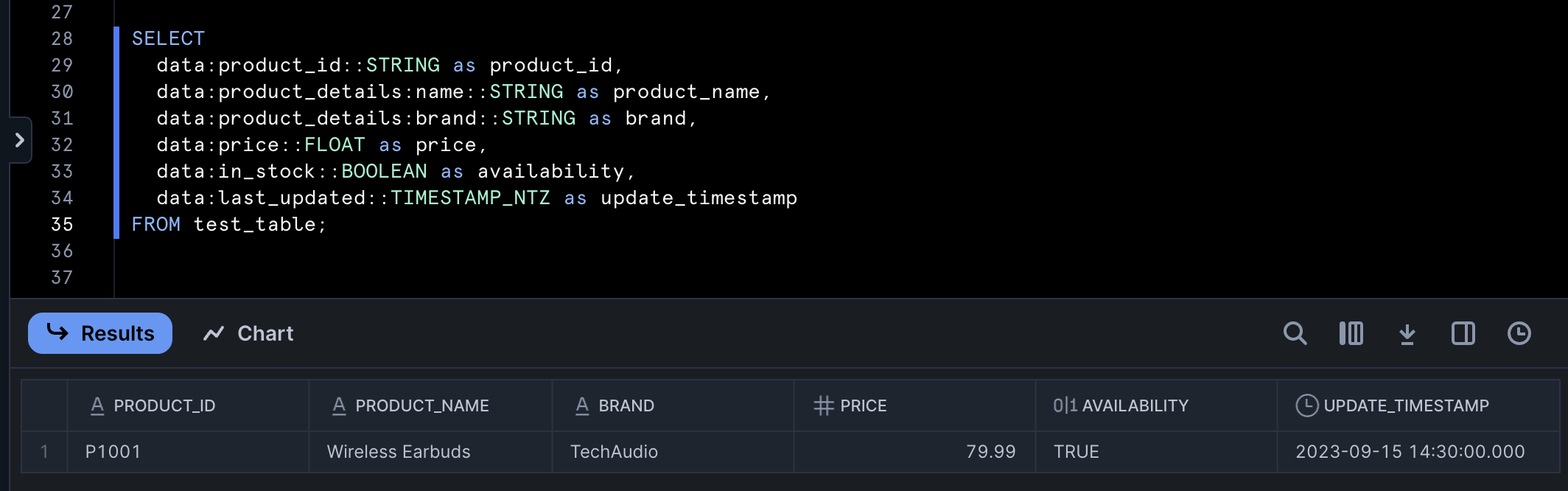
Parsed data in Snowflake using basic path extraction
Approach 2: Flattening JSON arrays
E-commerce product data frequently includes arrays of elements like product variants, specifications, or customer reviews that need to be transformed into individual rows for analysis.
Example JSON Data:
{
"product_id": "P1001",
"product_name": "Wireless Earbuds",
"variants": [
{"sku": "WE-BLK", "color": "Black", "price": 79.99},
{"sku": "WE-WHT", "color": "White", "price": 79.99},
{"sku": "WE-BLU", "color": "Blue", "price": 84.99}
]
},
{
"product_id": "P1002",
"product_name": "Mobile Phone",
"variants": []
}
Parsing Approach:
Use LATERAL FLATTEN to expand arrays into rows:
SELECT
data:product_id::STRING AS product_id,
data:product_name::STRING AS product_name,
f.value:sku::STRING AS sku,
f.value:color::STRING AS color,
f.value:price::FLOAT AS variant_price,
f.index AS variant_index -- the position in the original array
FROM test_table,
LATERAL FLATTEN(input => data:variants) AS f;
The FLATTEN function creates a cross-join between the base table and the elements of the specified array. Each array element becomes a separate row, while preserving all the parent object’s attributes. This approach is great for normalizing JSON arrays into relational table structures for analysis.
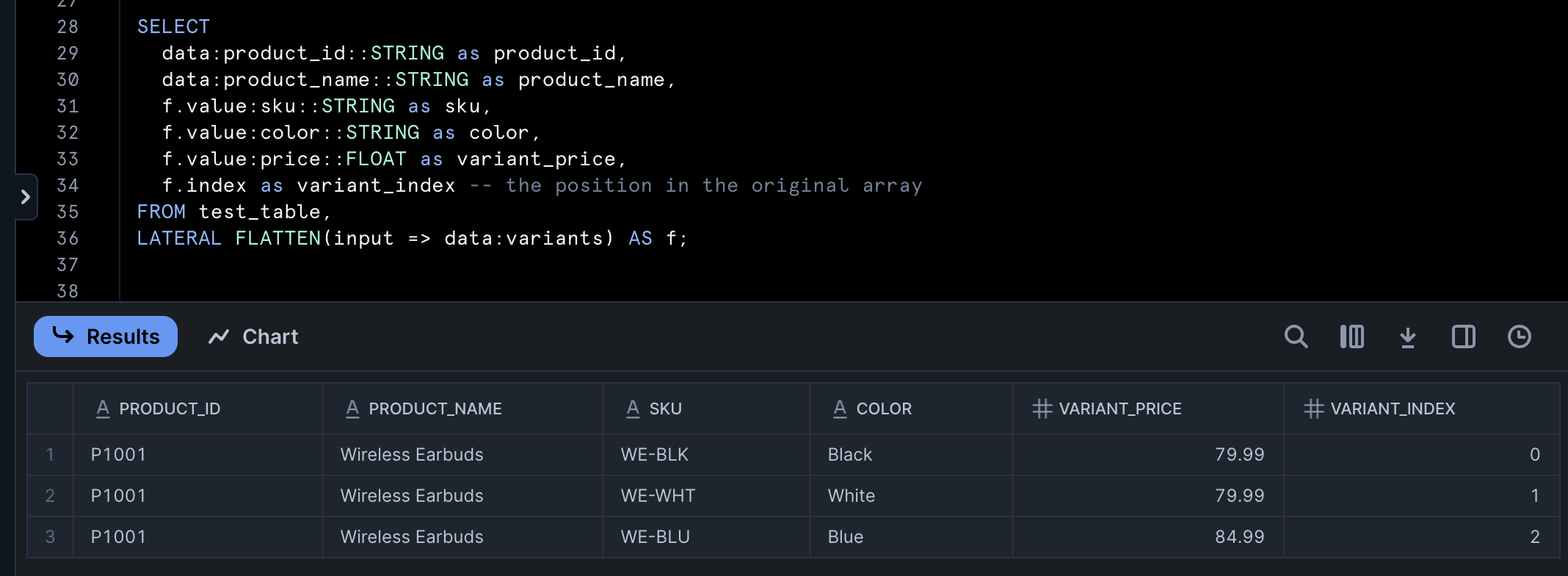
Parsed data in Snowflake using the FLATTEN function
If you know that some arrays in your data might be empty, you should use an optional OUTER flag in the LATERAL FLATTEN function to preserve such parent records:
LATERAL FLATTEN(input => data:variants, OUTER => TRUE) AS f;
That will create rows for all parent records in your data, but will display NULL values for rows with empty arrays (see the product_id P1002 in the image below):
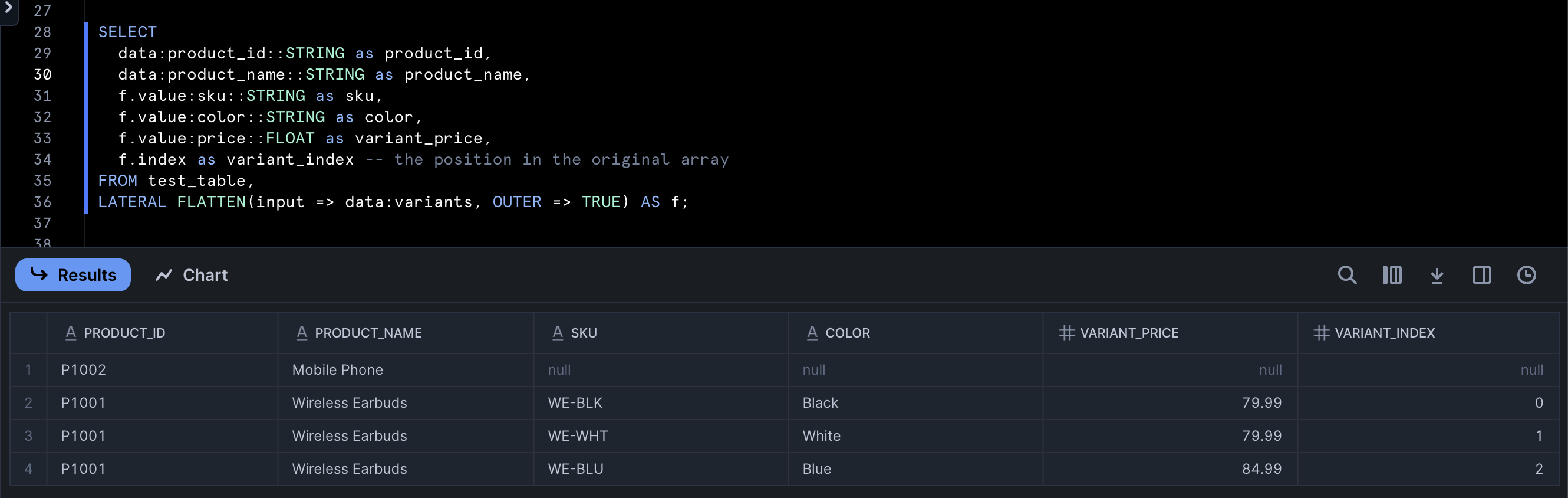
Parsed data in Snowflake with all parent records
Approach 3: Handling complex nested structures
Complex e-commerce data might include hierarchical structures like category trees, product specifications with nested attributes, or detailed inventory data across multiple warehouses.
Example JSON Data:
{
"product_id": "P1001",
"product_name": "Wireless Earbuds",
"category_hierarchy": [
{
"name": "Electronics",
"subcategories": [
{
"name": "Audio",
"subcategories": [
{"name": "Headphones", "id": "CAT-HP"},
{"name": "Earbuds", "id": "CAT-EB"}
]
}
]
}
]
}
Parsing Approach:
You can chain multiple LATERAL FLATTEN operations to navigate through nested arrays:
SELECT
data:product_id::STRING AS product_id,
data:product_name::STRING AS product_name,
l1.value:name::STRING AS category_l1,
l2.value:name::STRING AS category_l2,
l3.value:name::STRING AS category_l3,
l3.value:id::STRING AS category_id
FROM test_table,
LATERAL FLATTEN(input => data:category_hierarchy) AS l1,
LATERAL FLATTEN(input => l1.value:subcategories) AS l2,
LATERAL FLATTEN(input => l2.value:subcategories) AS l3;
This technique allows you to unfold deeply nested structures level by level, where each LATERAL FLATTEN operation exposes the next level of hierarchy. However, you should be mindful of potential data explosion if multiple levels contain arrays with many elements. In such cases, consider filtering early on in the query or flattening specific branches as separate tables.
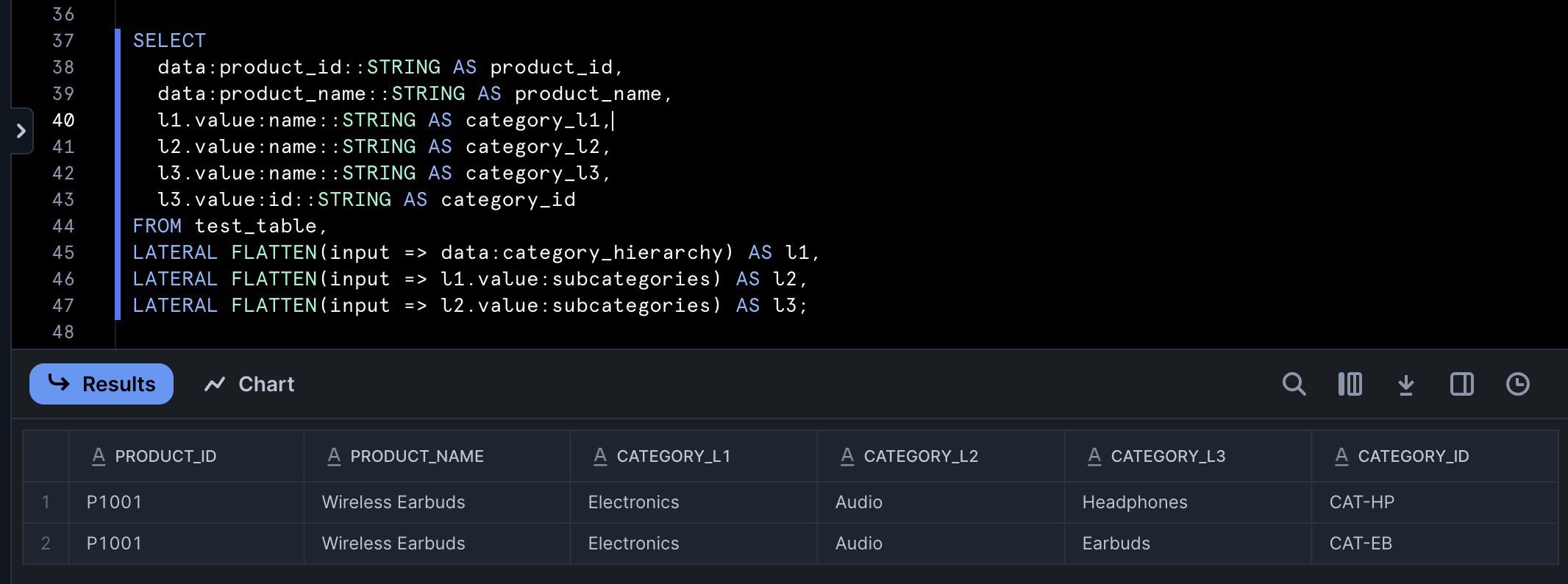
Parsed multi-level hierarchical data in Snowflake
Approach 4: Working with semi-structured data functions for dynamic field processing
E-commerce products often have variable attributes depending on the product type. For example, electronics might have technical specifications, while clothing has size and fabric information.
Example JSON Data:
{
"product_id": "P1001",
"product_name": "Wireless Earbuds",
"specifications": {
"battery_life": "24 hours",
"connectivity": "Bluetooth 5.0",
"water_resistant": true,
"supported_devices": ["Android", "iOS", "Windows"]
}
}
Parsing Approach:
Leverage OBJECT_KEYS and GET functions to handle dynamic attributes:
SELECT
data:product_id::STRING AS product_id,
data:product_name::STRING AS product_name,
keys.key AS specification_name,
CASE
WHEN IS_ARRAY(data:specifications[key])
THEN ARRAY_TO_STRING(data:specifications[key], ',')
WHEN IS_BOOLEAN(data:specifications[key])
THEN data:specifications[key]::STRING
ELSE data:specifications[key]::STRING
END AS specification_value
FROM test_table,
LATERAL FLATTEN(input => data:specifications) AS keys;
This approach is powerful for handling JSON objects with unknown or variable schemas. The OBJECT_KEYS function returns all the keys from a JSON object as an array, which we then FLATTEN into rows. This transforms key-value pairs in the JSON object into rows in the result set, allowing for dynamic processing of attributes without hardcoding them in the query.
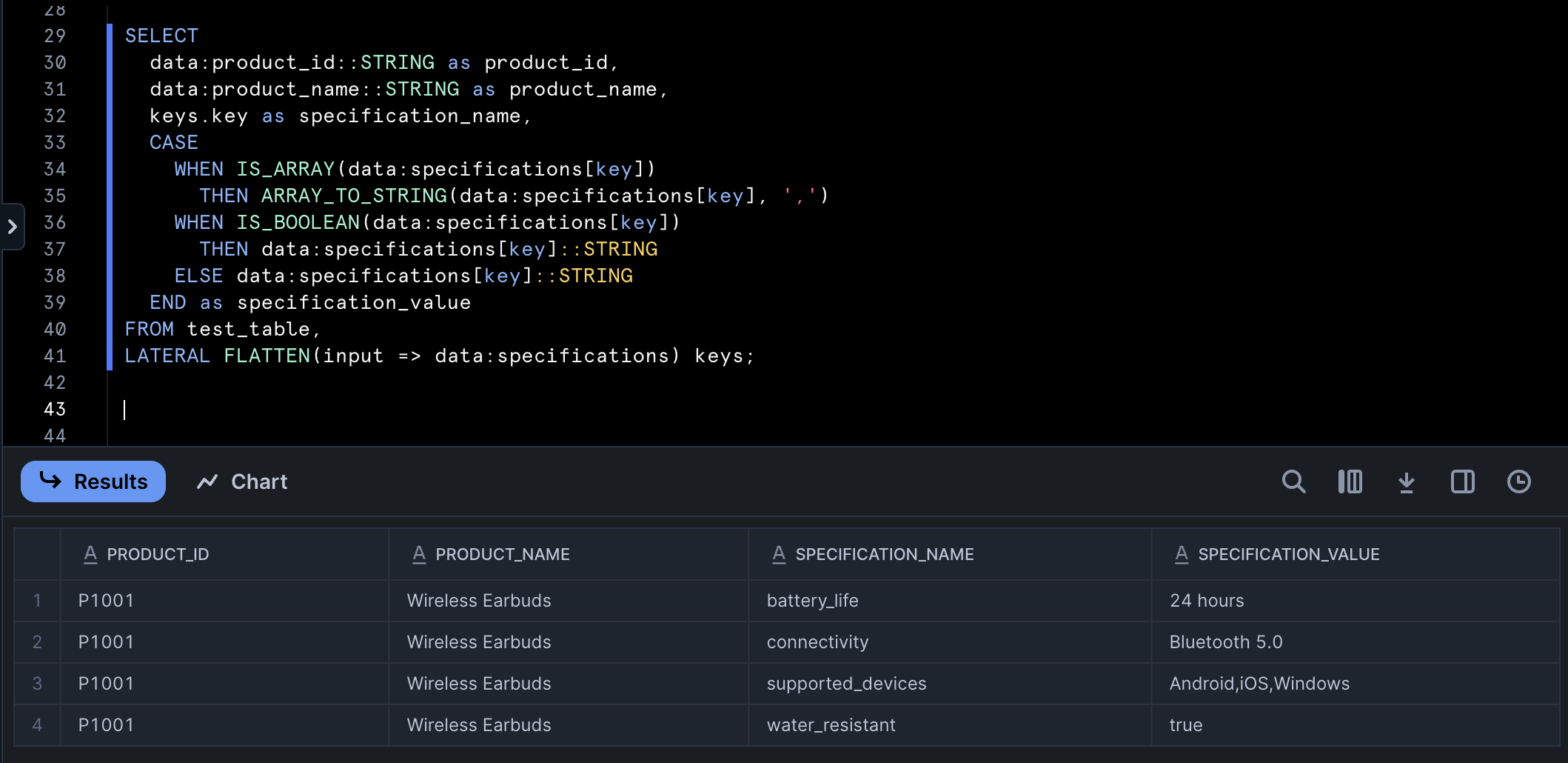
Parsed data with dynamic field names in Snowflake
Approach 5: Using SQL JSON Functions
Sometimes you need to not just extract data from JSON but also transform or enrich it. For example, when creating a product summary view that combines information from multiple nested fields.
Example JSON Data:
{
"product_id": "P1001",
"product_details": {
"name": "Wireless Earbuds",
"brand": "TechAudio",
"launch_date": "2023-01-15"
},
"pricing": {
"retail": 99.99,
"current": 79.99,
"currency": "USD"
},
"inventory": {
"total_stock": 245,
"warehouses": ["US-EAST", "US-WEST", "EU-CENTRAL"]
}
}
Parsing Approach:
Here you can apply PARSE_JSON and TO_JSON functions to transform your data to the required shape. You can also use the TRY_PARSE_JSON function instead of PARSE_JSON to return NULL values if there is an error during parsing.
SELECT
data:product_id::STRING AS product_id,
-- Extract data from various sections
data:product_details:name::STRING AS product_name,
data:pricing:current::FLOAT AS current_price,
data:inventory:total_stock::INTEGER AS stock_count,
-- Create a new JSON structure with computed values
PARSE_JSON(TO_JSON(OBJECT_CONSTRUCT(
'name', data:product_details:name,
'brand', data:product_details:brand,
'discount_pct', ROUND(100 * (data:pricing:retail::FLOAT - data:pricing:current::FLOAT) / data:pricing:retail::FLOAT, 1),
'warehouse_count', ARRAY_SIZE(data:inventory:warehouses),
'is_new_product', DATEDIFF('day', data:product_details:launch_date::DATE, CURRENT_DATE()) < 90
))) AS product_summary
FROM test_table;
This technique allows you to create new JSON objects that combine and transform data from the source column. The OBJECT_CONSTRUCT function builds a new JSON object with specified keys and values, which can be derived from the source data or even calculated dynamically as you parse it. This is can be particularly useful when working with API responses.
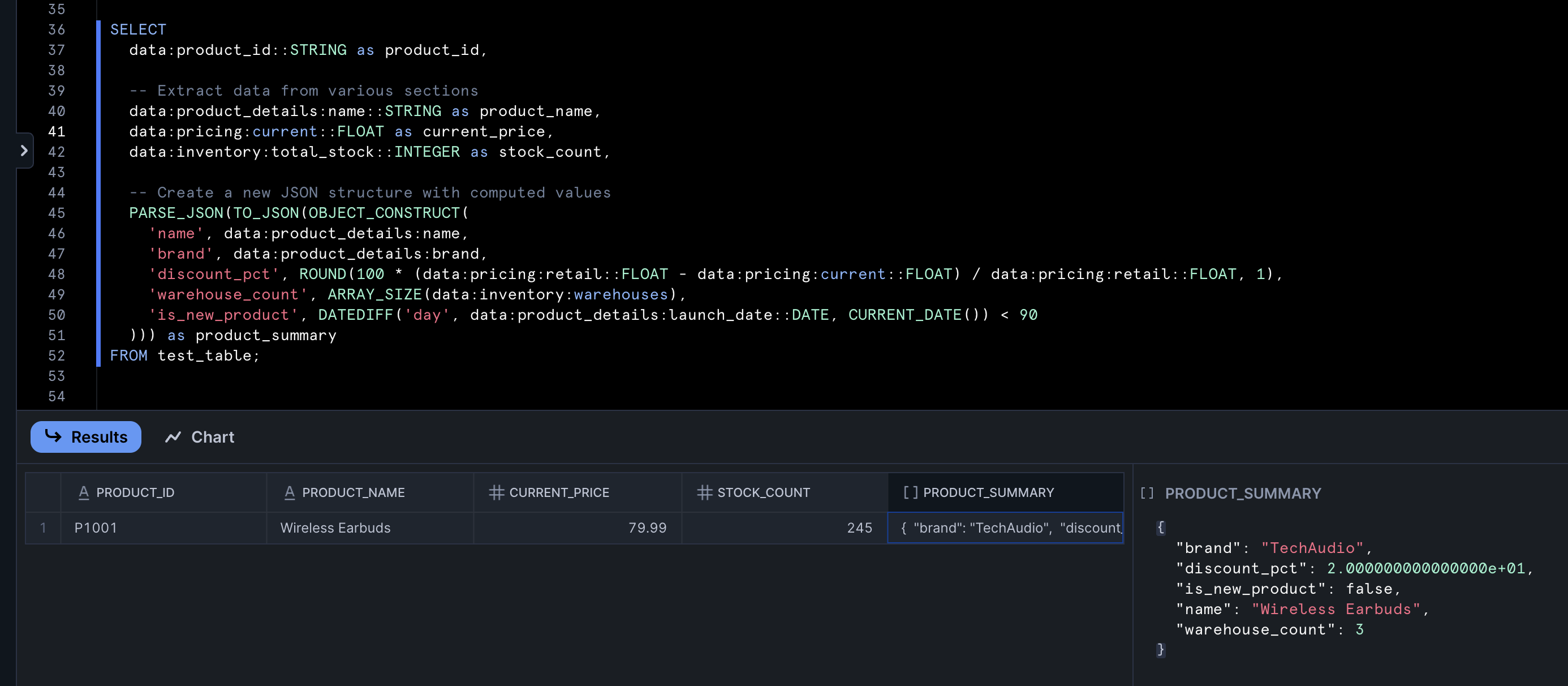
Parsed data in Snowflake using SQL JSON functions
Conclusion
As you can see from the examples above, Snowflake provides a robust functionality for handling JSON data of varying complexity in e-commerce and other domains. By mastering the described methods, you can efficiently transform JSON data into structured formats for advanced analytics, reporting, and machine learning.
Illustration by Storyset